Computerized Neurocognitive Testing in the Management of Concussions, Part 2
August 25, 2013

Concussion management for football,
c. 1930
I woke up this morning to my usual Sunday routine: the New York Times Sports page and coffee.
Today’s sports section–and I don’t think the Times is alone in this regard–is devoted to the subject of the forthcoming American college football season. The first games of the season will take place this Thursday, August 29. As the Times puts it, “The nation’s annual rite of mayhem and pageantry known as the college football season begins this week…..”
When I’m not doing work with the Clinical Journal of Sports Medicine, I’m taking care of youth, high school and college athletes; for my colleagues and me, the football season has already begun, with the various teams we cover already having had weeks of steady, increasingly intense practices and scrimmages. And we’re seeing the injury results of the sport, including an increase in volume of concussions.
I’ve mentioned this in my blog posts for this month, where the theme has been ‘concussions.’ Last week I wrote about the special set of CJSM concussion research articles we have made freely available for a limited time. At the beginning of the month, I authored a post on the subject of computerized neurocognitive testing (e.g. ANAM4, CNS-Vital Signs, AxonSports, ImPACT, etc.) and their use in managing concussions. I want to return to that subject in today’s post.
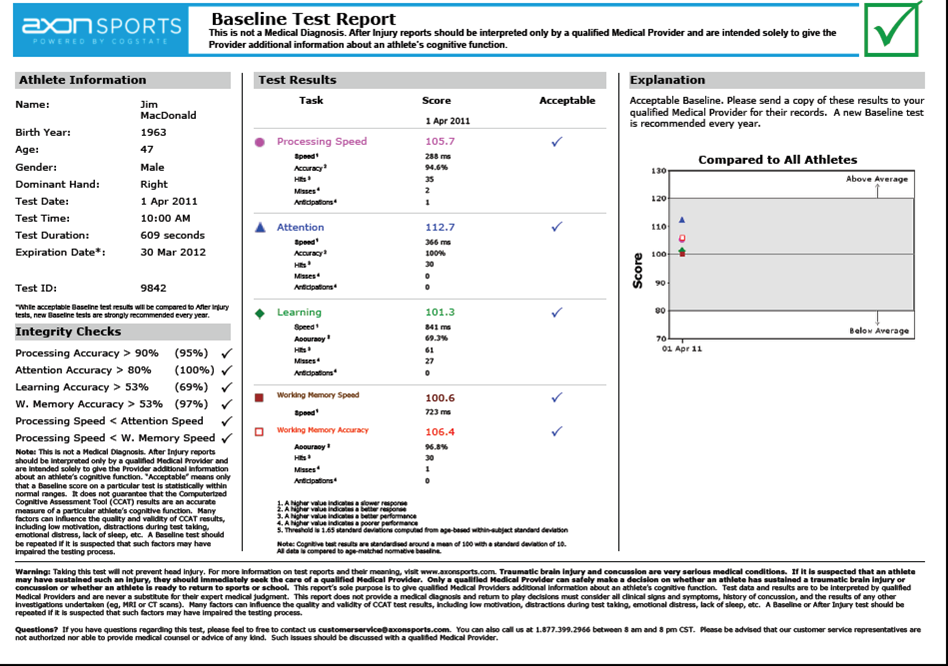
The author’s baseline AxonSport report
A recent article from the Archives of Clinical Neuropscyhology was especially interesting, I thought. The authors looked at a military population while evaluating the test-retest reliability of four computerized neurocognitive assessment tools (NCATs): Automated Neuropsychological Assessment Metrics 4 (ANAM4), CNS-Vital Signs, CogState (available now in the U.S. as ‘Axon Sports’), and ImPACT). I’m familiar with these products, but most especially ‘know’ CogState, as this is the NCAT we use in our clinic.
The authors correctly assert that test-retest reliability is one of the “…fundamental psychometric characteristics that should be established in each NCAT,” and that “….reliability should be established before making conclusions about a test’s validity,” which is the psychometric construct that can indicate whether a test measures what one is truly trying to measure (for instance, ‘reaction time,’ or ‘memory’). Reliability, is the “…extent to which the test produces consistent results across multiple administrations to the same individual.”
In this study of 215 individuals (mean age 34, range 19 to 59), the authors divided the study population into groups of four, each group containing approximately 50 individuals. Within each group, the study participants took one of the four NCATs being evaluated at day 1 and again 30 days later. The authors then calculated intraclass correlation coefficients (ICCs) for each of the subscores that can be calculated for the respective tests. For instance, in CogState (AxonSports), a composite score can be calculated, as well as individual scores for ‘detection speed,’ ‘identification speed,’ ‘one card learning accuracy,’ and ‘one back speed.’ ICCs have more or less become the standard statistical measure of test-retest reliability.

Checking reaction the ‘analog’ way;
technique courtesy of Eckner et al.
The findings were significant for the absence of any score in any one of the subtests for any of the NCATs to achieve a ‘very high’ degree of reliability (ICCs can range from 0 – 1, with an ICC of 0.9 to 0.99 considered ‘very high’). In the case of CogState, for instance, ICCs for the five scores described above were mostly in the range of 0.74 – 0.79 (‘adequate’), but one score, the ‘one card learning accuracy,’ had a very weak ICC of 0.22. The authors note that their findings are similar to those reported in other studies of test-retest reliability in other populations. They conclude, I think correctly, that their reported reliability measures for the four NCATs tested “…are lower than desired for clinical decision-making.”
I think this is a well-designed study. There are limits to how generalizable the specific results are to my clinical practice–the average age of the patient I treat is 14.5, with a range from 6 to 25 years (markedly different than the paper’s study population). That said, the article contains a wide-ranging review of the literature, and places its findings within the context of the larger literature. Reliability measures–a fundamental property of any test we would want to use in this arena–are relatively weak for the existing NCATs.
Reliability, validity, and responsiveness (the ability of a test to measure clinically meaningful change in the subject) are the pillars of health care outcomes measurement. Kathryn Roach, Ph.D., gives a fine, brief tutorial on these concepts here. I’ve discussed already the limitations of reliability as found in this study of NCATs; as the study authors conclude, “…reliability is only a piece of the psychometric puzzle. A highly reliable test is clinically useless if it is not also valid.”
I hope to look soon at whatever recent studies might exist on the validity of these NCATs. Most studies of validity are conducted on the ‘criterion validity of a test: that is, does one test’s outcomes track another test’s outcomes.
In the mean time, may I make a plug that you check out the research of J.T. Eckner and colleagues from the University of Michigan. They have been looking at a simple test of reaction time over the past several years. Among the many papers they have published, there is a particularly interesting one entitled Can a Clinical Test of Reaction Time Predict a Functional Head Protective Response? It is essentially a test of construct validity, arguably a more powerful measure than criterion validity: does the test measure what it is purported to measure? In brief, the authors use a simple device to measure reaction time (RTclin) (see photo inset; I have been able to conduct some research on this device as well courtesy of an AMSSM Young Investigator grant). They then measured the subjects’ ability to block a foam projectile launched from an air cannon at their head!!! The authors argued that this would provide a quantifiable measure of a functional response (RTsprt), something that might mimic, for instance, the reaction time a wide receiver may require to catch a ‘bullet’ thrown by a quarterback.
The authors found a strong positive correlation between RT(clin) and RT(sprt) (Pearson’s r = 0.725, P < 0.001) independent of age, gender, height, or weight. A correlation coefficient of r = 0.725 represents a moderately strong association, and the design of the study is truly representative of a test of construct validity, something that can be very difficult to measure. Kudos to the folks from U of M.
The holy grail for concussion managment: a test with excellent sensitivity and specificity, and one with good reliability, validity and responsiveness. It doesn’t exist yet. But for those of us who enjoy the research side of clinical sports medicine, that just means we have a lot of questions to answer, work to do, studies to publish…..and blog posts to write. Keep your eyes peeled on the Clinical Journal of Sports Medicine as we continue to publish high quality research in this and other areas.
